在我们日常使用计算机的过程中,经常会涉及到各种数据类型,其中最常见且基础的就是整型(integer)。然而,你知道吗?在整型这一大类下,还存在着无符号整型和有符号整型这两种类型,它们各自拥有独特的特性和应用场景。今天,我们就来深入探讨一下这两种整型之间的差异,揭开它们背后的秘密。
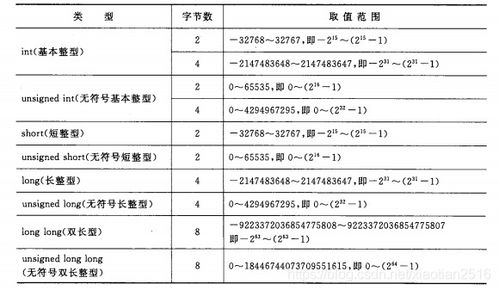
1. 数字范围的差异
首先,让我们来看看两者在数值范围上的不同。无符号整型(unsigned integer)可以存储从0到最大值的所有整数,具体的最大值取决于所使用的位数。例如,一个8位无符号整型可以存储从0到255的数值;而一个32位无符号整型则可以存储从0到4294967295的数值。相比之下,有符号整型(signed integer)则包含了正数、负数以及零。同样以32位为例,它能够表示的范围是从-2147483648到2147483647。这意味着,在相同位数的情况下,有符号整型会损失一半的正数范围来容纳负数。
2. 存储方式的不同
接下来,我们来看一看这两种整型是如何在计算机内部进行存储的。对于有符号整型来说,最常用的一种编码方式是二进制补码(two\'s complement),它通过最高位(即最左边的一位)来表示数字的正负。如果最高位为0,则该数为正数;如果为1,则为负数。而对于无符号整型,所有的位都用于表示数值本身,没有额外的信息用来标识正负。
3. 应用场景的差异
最后,让我们来看看它们各自的应用领域。由于无符号整型可以存储更大的非负数值,因此常被用于需要表示数量、大小或时间戳等场景,如文件大小、内存容量等。相反,有符号整型因其能够同时表示正数和负数的特点,在处理温度变化、金融交易金额、坐标定位等需要考虑正负值的情况时更为适用。
结语
通过以上分析,我们可以看到无符号整型和有符号整型虽然都是整型家族的一员,但它们在数值范围、存储方式以及应用场景上都有着明显的区别。理解这些差异有助于我们在编程实践中更合理地选择合适的数据类型,从而提升程序的效率和准确性。希望本文能帮助你更好地掌握这两种重要的数据类型,让你在未来的编程之旅中更加游刃有余!






















